
Corpus Methodology
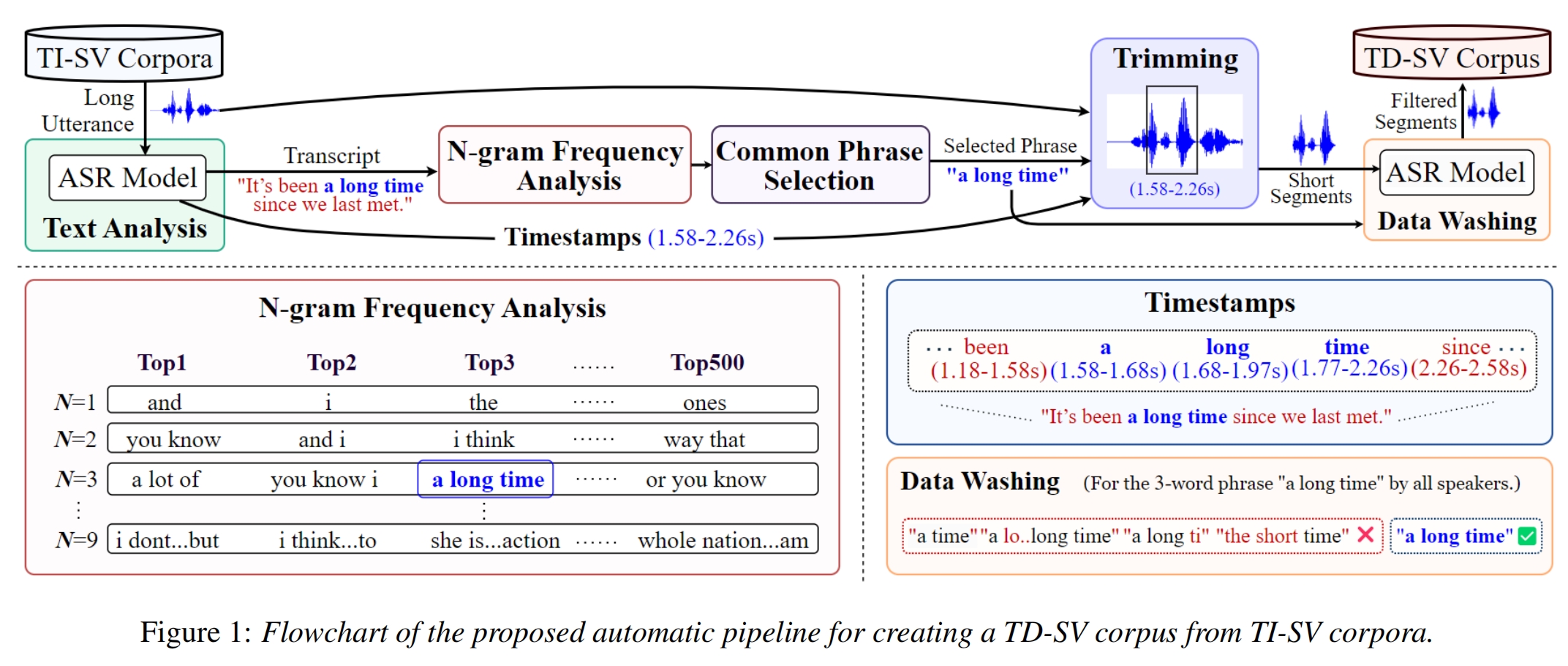
The flowchart of our proposed automatic pipeline is shown in Figure 1. It contains four steps, which will be explained further in the following subsections. It contains four steps, which will be explained further in the following subsections.
Derive TD Corpora from TI Corpora
To overcome the size limitation of existing TD-SV corpora, we must expand speaker diversity, recording quantity, and usage scenarios. In particular, we require a substantial increase in the number of speakers and more diverse recordings. Such requirements can be fulfilled by leveraging the resources in large TI corpora.
Speech-to-Text
Text-dependent corpora put more emphasis on lexical content than text-independent ones. Extracting the text from utterances is the first step of the pipeline if the TI corpora do not have word-level transcriptions, e.g., VoxCeleb. Various self-supervised learning (SSL) front-ends can be used for this task, including wav2vec 2.0, WavLM, HuBERT, and Whisper. We used Whisper from OpenAI to perform speech-to-text and to obtain the timestamps of every word.
However, the Whisper model has auditory hallucination problems, which is a common issue in large speech models. Common hallucinations include transcribing the same sentence over and over again, repeating inexplicable content in non-speech regions, etc. To address this issue, voice activity detection (VAD) was used to distinguish between speech and non-speech segments in a conversation. By separating speech and non-speech segments in advance, auditory hallucinations in the Whisper model can be reduced.
N-gram Frequency Analysis
We must select as many common phrases as possible from the TI corpus to diversify the use cases of the curated TD corpus. In a TI corpus, different speakers often utter different sentences. However, in a TD system, the text of a test utterance must match the registered text of the target speaker. Therefore, it is crucial to have enough phrases spoken by the same and different speakers to form various test trials in a TD corpus. To this end, every phrase must be spoken by a speaker at least twice. We searched for the commonly used phrases, sorting the top 500 phrases for each N-word phrase, where N=1,2,…,9.
Trimming
To obtain the recordings of the selected phrases, we trimmed the corresponding segment according to the timestamps of each phrase to form the test utterances. We made the directory structure of the proposed Sub3Vox as consistent with VoxCeleb1 as possible.
Data Washing
To reduce the detrimental effect of ASR errors on the curated dataset, we added data filtering at the end of the automated pipeline to check if the trimmed utterances correspond to the N-word phrases transcripted by the ASR model (see Figure 1). This double check procedure can further uncover some problematic and unusual cases caused by auditory hallucinations. As mentioned earlier, if the phrases were wrongly transcribed due to hallucinations, they will be different from the recognized phrases of the trimmed segments, which will be deleted by the filtering module.