Protocols of TI-SV and TD-SV
In TD-SV, both the speaker and the spoken content are considered. As shown in Table 2, TD-SV has four trial types: target-correct (TC), imposter-correct (IC), target-wrong (TW), and imposter-wrong (IW). The system accepted a test speaker only when he/she spoke the correct phrase (TC) during verification.

Lower equal error rate (EER) and minimum decision cost function (minDCF) indicate better performance. Since Sub3Vox is derived from VoxCeleb1 and the model is pre-trained on VoxCeleb2, it simulates real-life scenarios with unseen speakers and passwords. Testing on future Sub3Vox versions derived from VoxCeleb2 should yield better performance with lower EER and minDCF.
Performance Metrics
The equal error rate (EER) and minimum detection cost function (minDCF) were used to measure the performance of the model. The parameter setting of minDCF follows RSR2015, where $C_{Miss}=10$ is the cost of missing a target speaker, $C_{FA}=1$ is the cost of false acceptance, $P_{Target}=0.01$ is the prior probability of target speakers, which means that the probability of the correct target speaker appearing in practical applications is 0.01. Lower equal error rate (EER) and minimum decision cost function (minDCF) indicate better performance.
Performance
When using VoxCeleb to build and evaluate SV systems, models are typically trained on VoxCeleb2 and tested on VoxCeleb1. Specifically, VoxCeleb2’s dev and test sets are used for training, while VoxCeleb1’s dev and test sets are used for testing. We used pre-trained models from VoxCeleb2 in WeSpeaker (ECAPA1024_LM and ResNet221_LM) to test the performance on the curated Sub3Vox. The supported scoring back-end is cosine similarity with score normalization.
We tested text-dependent and text-independent speaker verification to compare metrics under the same and different phonetic contexts, respectively. For enrollment, we used three different utterances of the same passphrase from the same speaker, with one passphrase as the test utterance.
Overall Performance
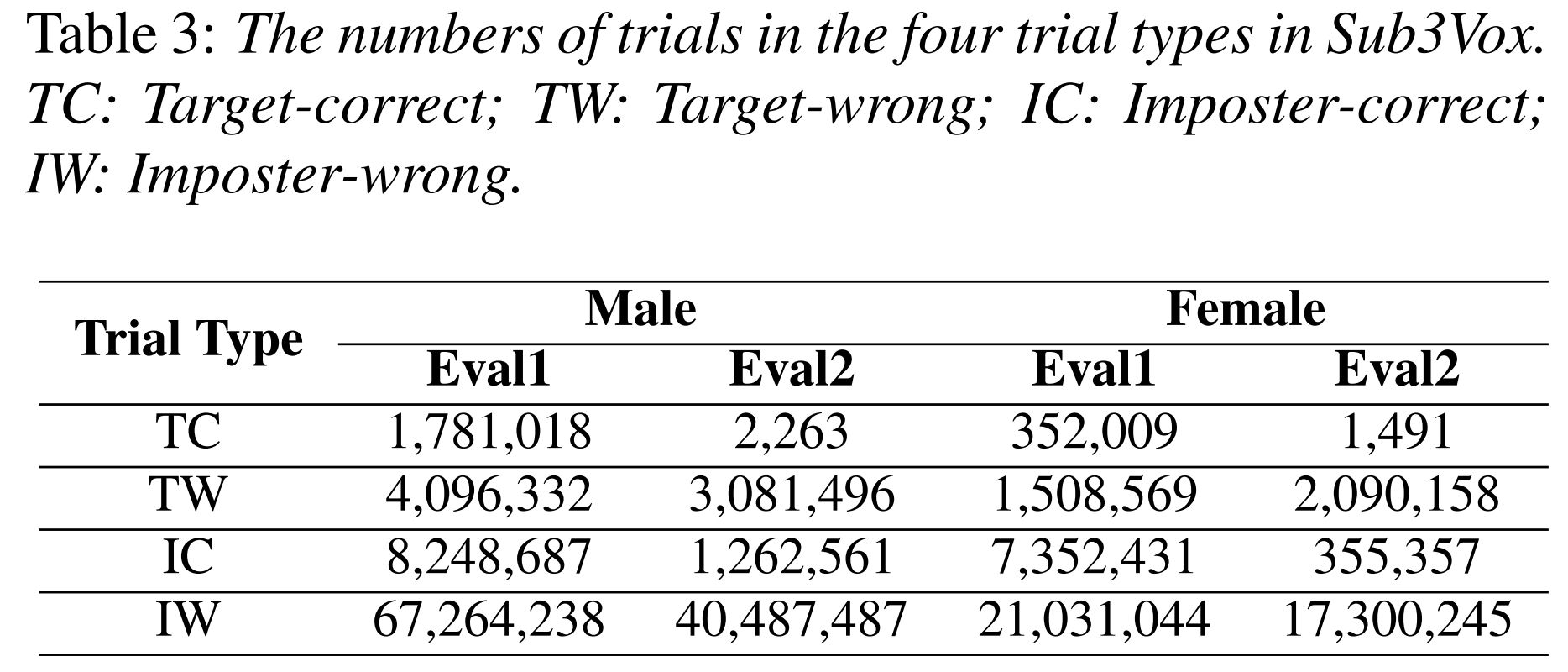
The number of trials are shown in Table 3. Table 4 shows the performance of two SV systems that use 2-word to 8-word as the passphrases. The 1-word phrases, such as “and”, “the”, etc., were excluded because they are rarely used in speaker verifica- tion.
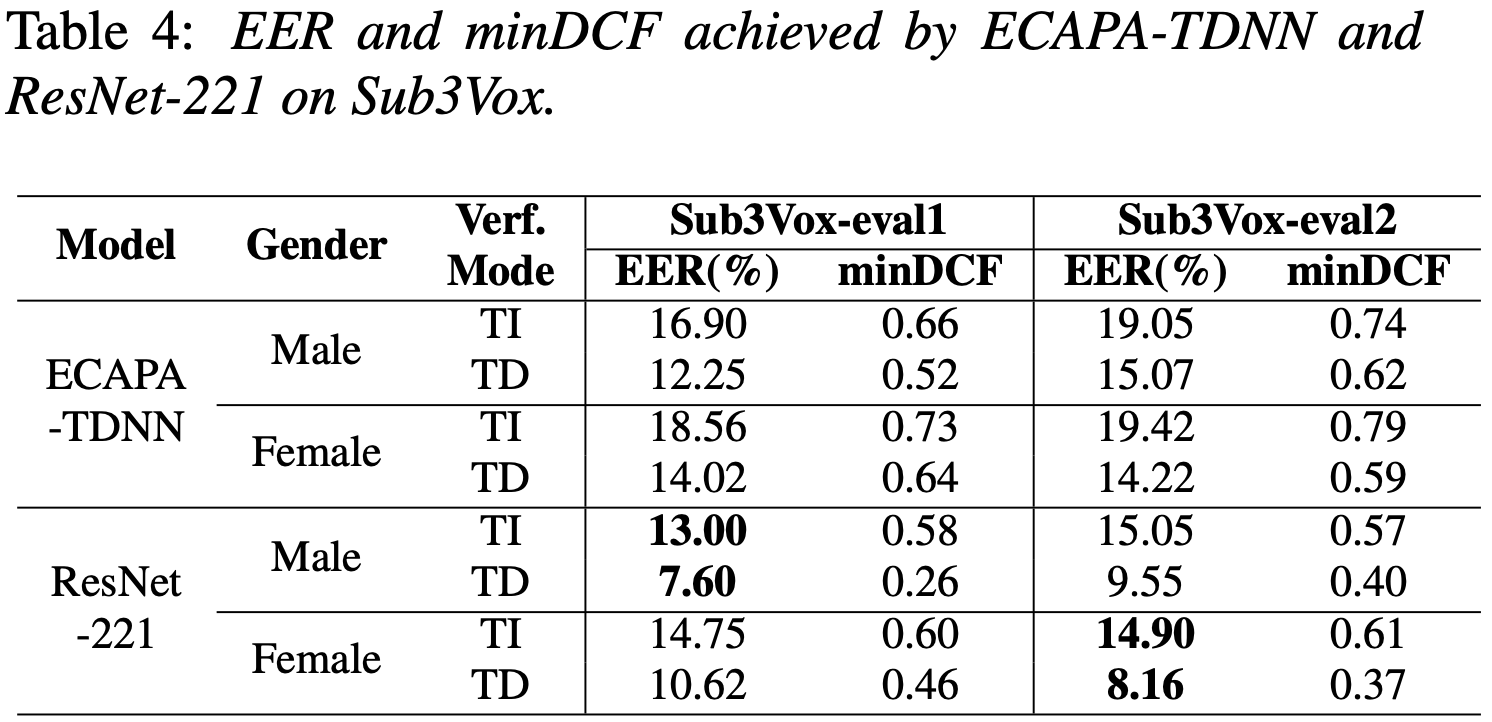
Compared with TI-SV, the performance improvement of the TD-SV is over 30%, which is consistent across gender and evaluation subsets. The highlighted example in Table 4 reaches a performance improvement of 45.23% for the female speakers. Among the male speakers, the improvement is 41.54%. These results demonstrate that TD-SV has a significant advantage over TI-SV, especially when the test utterances are short. Because Sub3Vox was derived from VoxCeleb1 and the models were pre-trained on VoxCeleb2, Sub3Vox can simulate real-life scenarios with unseen speakers and passphrases. If Sub3Vox were derived from VoxCeleb2 instead of VoxCeleb1, the performance improvement achieved by the TD-SV systems could be more impressive.
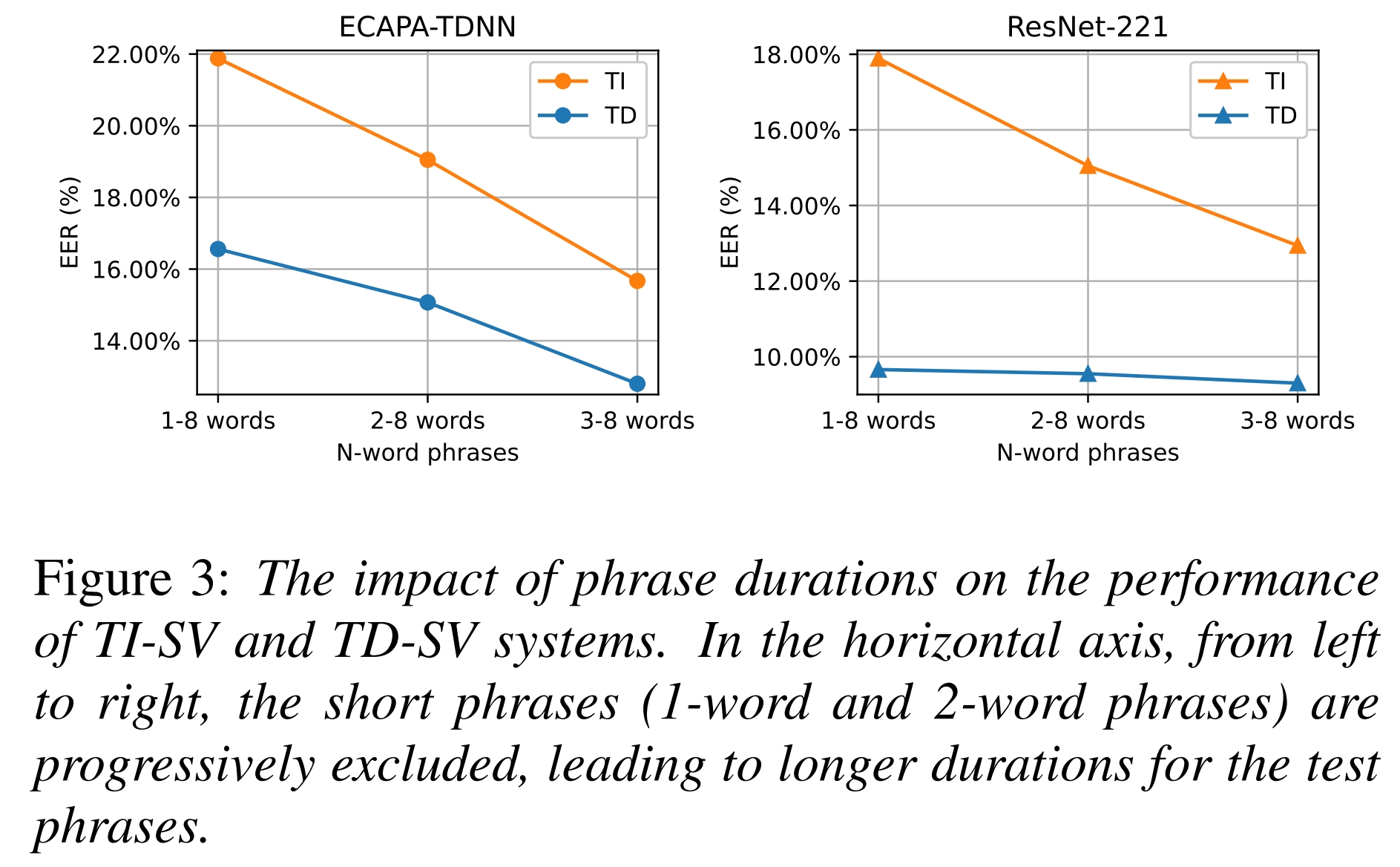
Figure 3 shows the impact of the number of words in a phrase on the performance under the TI-SV and TD-SV settings. The average utterance durations in Sub3Vox are 564ms for males and 587ms for females. At these mean durations, the expected numbers of words are 2.4 for both gender. Because the enrollment and test utterances have an integral number of words, we report the performance of TI-SV and TD-SV under 1–-8 words, 2–-8 words, and 3–-8 words in Figure 3. This arrangement means that the evaluations on 2–-8 words will exclude all 1-word phrases. Similarly, the evaluations on 3–-8 words will exclude all 1-word and 2-word phrases. The results show that the TI-SV system suffers from a more severe performance drop (increase in EER) when the evaluations include 1-word and 2-word phrases. The performance drop in TI-SV is even more severe when the evaluations include 1-word phrases, especially for the ResNet-211. This trend clearly suggests that TD-SV is a better choice for short-utterance scenarios.
Performance on Fixed Number of Words
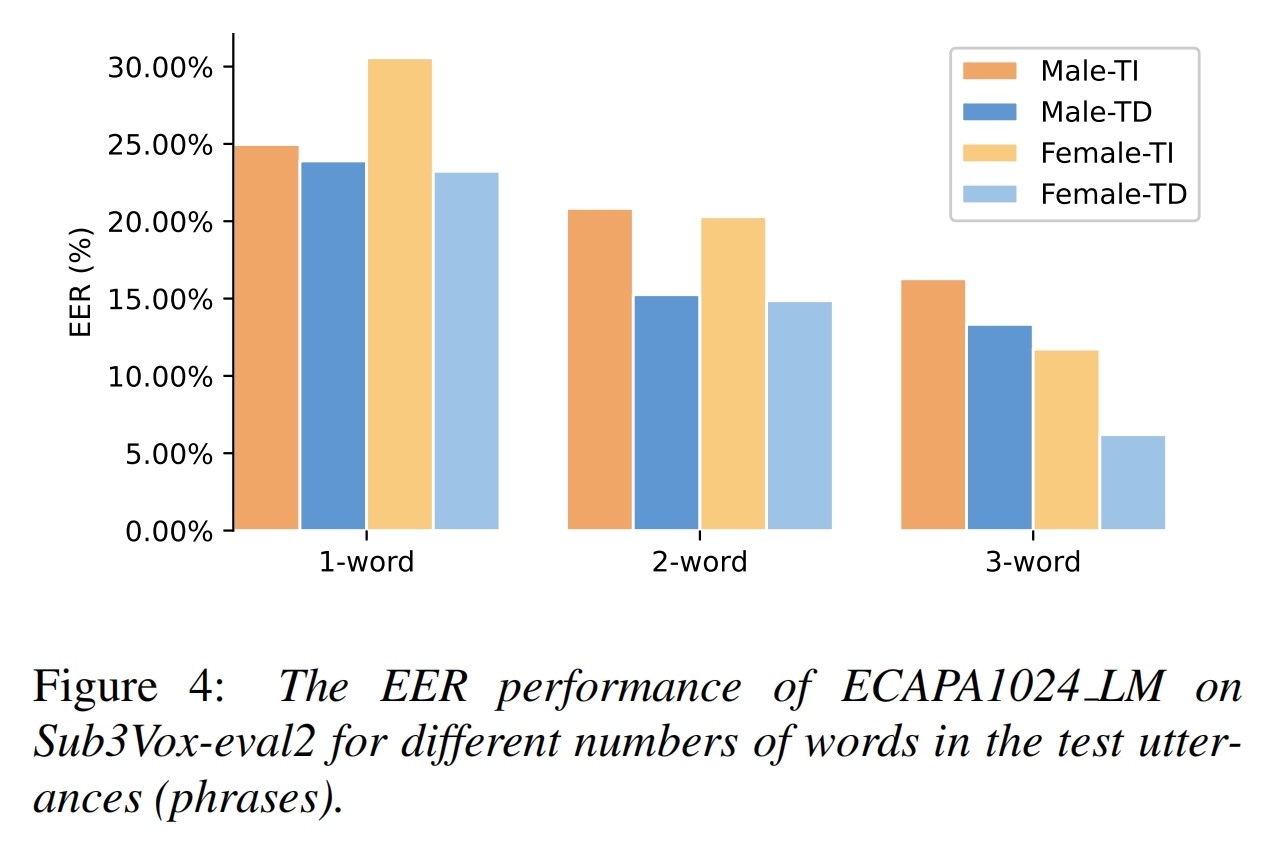
We also conducted experiments in which all trials used utterances with a fixed number of words, e.g., 1-word phrases, 2-word phrases, and 3-word phrases. The results are shown in Figure 4. Evidently, the EER decreases when the number of words in the phrases increases. Again, the performance of TD-SV is always better than that of TI-SV.